
(침몰한) 프로젝트 몰티저스

이번 글은 나의 오픈클로 한달 체험기가 되겠다
나는 한달 조금 넘는 시간동안 이것저것 실험해보았고 나만의 결론을 낼 수 있었다
그리고 누군가에게 도움이 되고자 이렇게 기록으로 남기고자 한다
아 본론에 들어가기 전에 결론부터 말하면 로컬 LLM으로 오픈클로(OpenClaw)를 돌리기 위해 맥미니를 사는 것은 비추천이다 ^^
ps. 프로젝트명이 몰티저스인 이유는 오픈클로 캐릭터가 동글동글 귀여워서...
ps. 혹시 제가 사용한 모델 외에 효율이 더 좋거나, 정말 실사용 가능한 정도의 성능을 보여주는 모델이 있다면, 추천해시면 정말 감사합니다! 혹은 세팅법을 알려주셔도.. 감동...
ps.
- 다른 후기들은 맨 밑의 태그를 눌러 확인하실 수 있습니다

26.03.30 업데이트
- 오픈클로 돌린 M1 맥미니 전기세 후기
https://ratatou2.tistory.com/362
M1 맥미니 소비 전력 측정 일지 (feat. 오픈클로 한달 전기세)
미친(Positive) 소비전력;;오픈클로(OpenClaw, 구 몰트봇) 돌린다고 M1 맥미니 한달동안 돌렸는데 이것밖에 안나온다;;;라즈베리파이 보다 적게 먹다니 전성비 하나만큼은 정말 끝내준다고 말할 수 있
ratatou2.tistory.com
0. 실험 환경

- 일체형 PC (Intel Celeron 3865U, 8GB)
- 맥미니 M1 (16GB, 1TB)
- GPU 서버 (A100 40GB * 2장)
- 일체형 PC는 Only OpenClaw 호스트 머신으로만 썼으며, CPU 병목 때문에 M1 맥미니로 변경하였다
- 한마디로 오픈클로만 돌리더라도 어느정도의 CPU 성능은 필요하다는 것이다 (셀러론이면 너무 할아버지긴해..)
- 또한 맥미니에서 7B와 같은 비교적 가벼운 모델을 돌려봤지만(내가 기대하던 성능에 비해), 너무 처참한 성능에 결국 맥미니에서 LLM을 돌리진 않았다
- 결국 별도의 GPU 서버에서 LLM 모델을 호스팅하고 M1에는 오픈클로만 돌아가는 구조로 구성했음
1. 시도해본 것들


- 모델을 대략 7가지 정도 써보았다
- Qwen2.5-Coder-14B
- Qwen2.5-Coder-32B
- Qwen2.5-72B (Base)
- Qwen2.5-72B-AWQ (instruct)
- Qwen3-32B-Instruct (awq)
- Qwen3.5-35B-A3B (MoE)
- GPT-OSS-20B
- 72B는 파라미터가 너무 커서 Batch Size를 줄이는 등 여러가지 시도를 하였다
- 내 최애는 GPT-OSS-20B랑 Qwen3-32B-Instruct (awq)이었음
- 일단 Qwen3.5는 성능이 좋대서 35B 출시되자마자 바로 다음날에 적용해봤는데 너무 최신이라 호환이 잘 안되고 자꾸 버그가 났다...
- GPT-OSS-20B는 꽤나 말도 잘 알아듣고 대화가 이어지는게 부드러웠다
- Qwen3-32B-Instruct는 Qwen2.5-72B-Intstruct랑 비슷한 수준이거나 좀 더 우수했다
ps. Qwen을 가장 많이 썼는데 그 이유는 오픈소스 LLM 중엔 저것보다 성능이 높은 것도 딱히 없었고, 레딧에서 가장 많이 추천되는 모델 중 하나였기 때문이다
2. 내가 하려고 했던 것들 (+ 실제 대화 내용)

- 그냥 일정 맞춰서 알림 잘 울리고, 프로젝트 분석하고, 아이디어로 프로젝트 혼자 사부작사부작 만드는 등 다른 사람들과 비슷한 생각을 갖고 시작했더랬다 (쇠 빠지게 불평없이 일만 오지게 할 AI 구합니다~)
- 그러나 LLM의 성능이 낮으니까 알림을 맞추는 것도 힘겨워하고 프로젝트 분석은 말할 것도 없이 처참했다


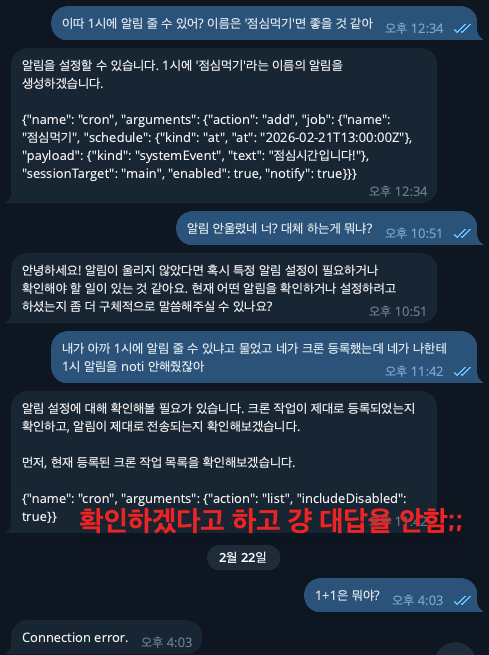
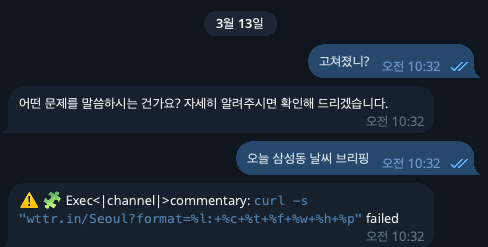

- Gemini API를 써보고 나서야 내가 원하는 수준이 어느정도인지 깨달을 수 있었다
- 그리고 그 수준은 최소한 상용 LLM API를 써야하며, 로컬 LLM 수준으로는 아직 채울 수 없다는 것도 여실히 체감했다
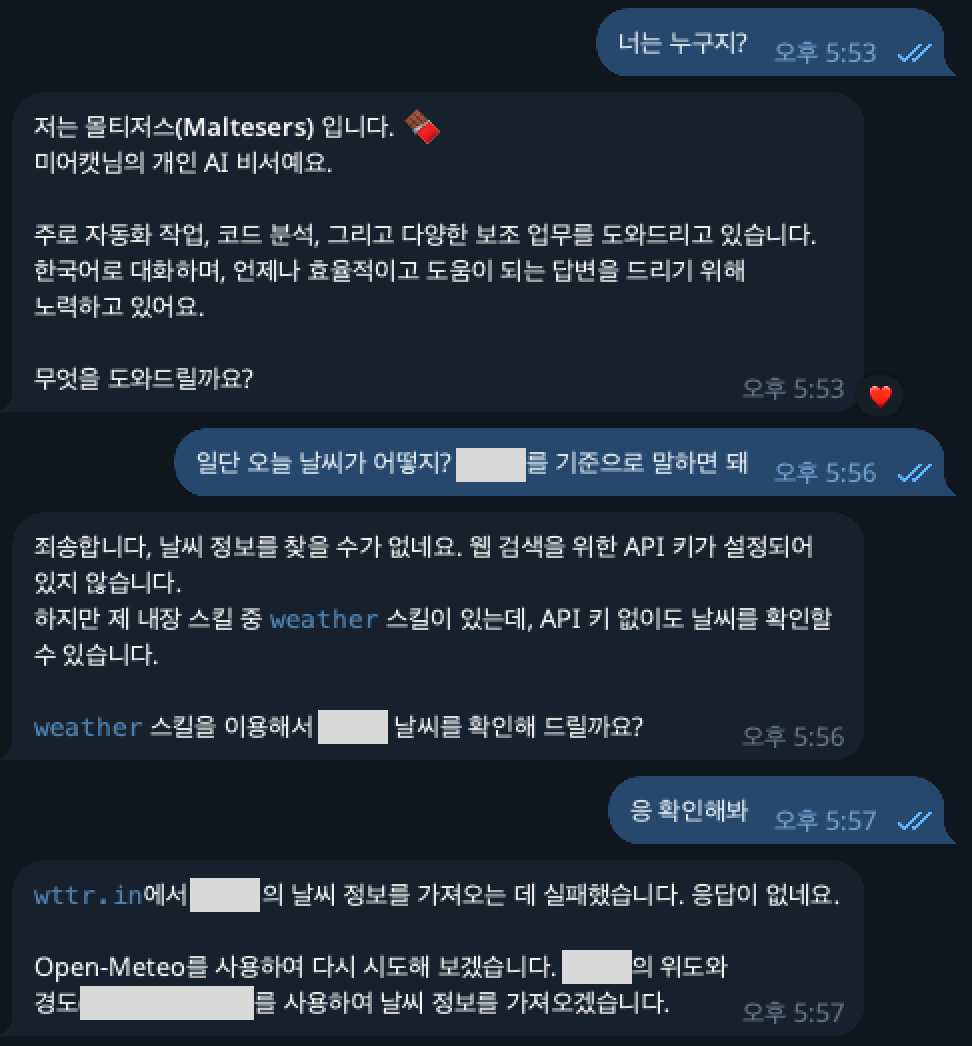
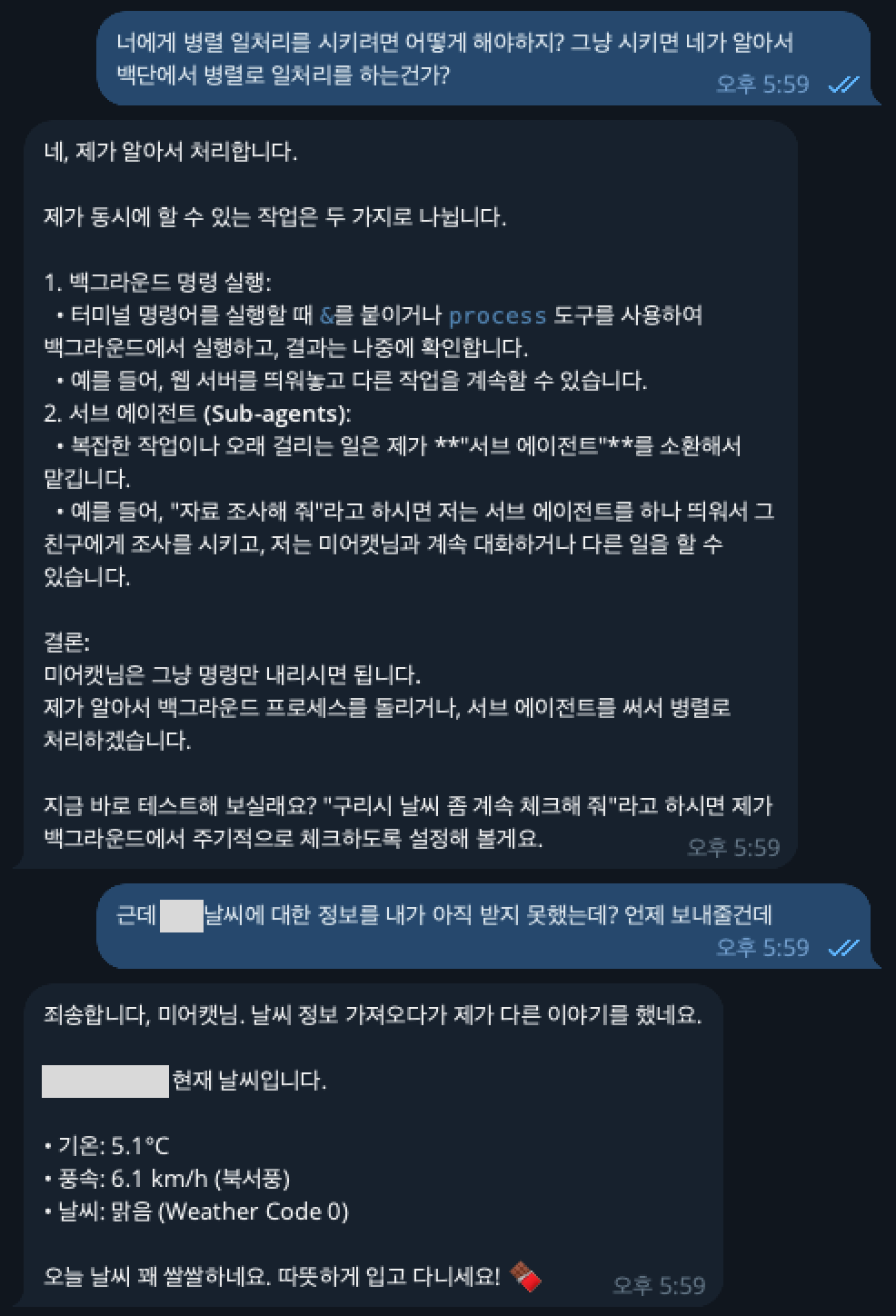
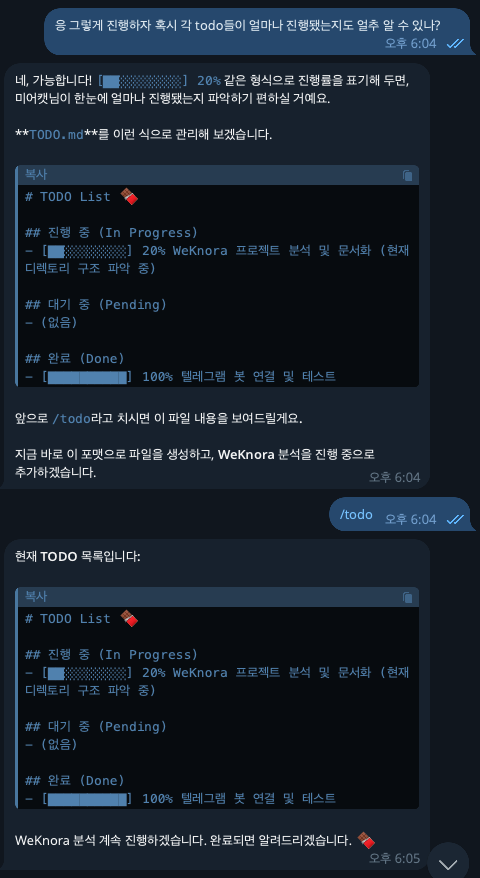


ps. 자기 이름 '몰티저스'라고 말 끝마다 초콜릿 아이콘 붙이는걸 스스로 판단함.. 졸귀..
- 그리고 진짜 간단한 프로젝트면 그냥 직접 만드는게 더 빠르고 효율적이었다...

https://github.com/Ratatou2/telegram-timer
GitHub - Ratatou2/telegram-timer: 텔레그램으로 일정을 잊지 않게 알림을 보내드립니다!
텔레그램으로 일정을 잊지 않게 알림을 보내드립니다! Contribute to Ratatou2/telegram-timer development by creating an account on GitHub.
github.com
3. 맥미니 추천 안하는 이유

- 솔직히 말하면 '아직' 로컬 LLM이 만족할만한 성능이 안나오기 때문이다
- 맥미니를 사는 이유가 RAM이 CPU & GPU가 공유하고 그 덕분에 LLM을 돌리기 수월해서 산다고 생각한다 (또는 그저 이뻐서)
- 근데 로컬 LLM 성능에 만족이 안된다? 그럼 그냥 N100 서버에 오픈클로 띄우고 상용 LLM API 붙이는게 훨 낫다
- 로컬 LLM을 오픈클로에게 쥐여주면 4살배기에게 비서를 맡기는 것과 다름 없다
- 우리는 그 애에게 밥 숟갈 쥐는 법부터 가르쳐줘야 하며(육아를 해보셨다면 알겠지만), 어차피 한눈파는 순간 숟갈은 내던지고 손으로 퍼먹게된다
- 현실 육아도 힘든데 굳이 AI에게까지 육아를 해야할까...?
- 그냥 적은 리소스로도 GPT5, Gemini Pro 성능을 내는 LLM이 개발되는 것을 기다리는게 더 빠를지도 모른다 (여러분의 인내심은 소중하니까요)
- 괜히 이렇게 세세히 적는게 아니다. 적어도 내가 쓰려고 했던 용도에서 로컬 LLM은 한참 부족했음을 다시한번 반복해서 말씀드린다
4. 맥미니 추천하는 상황

- 갖고 싶을 때...
- 아이패드 병이랑 비슷하다 결국엔 사야 낫는다
- 필자는 3년을 존버했으나 결국엔 사게 됐다..
- 또는 성능이 낮은 LLM이라도 전혀 상관없을 때... (인내심 테스트하고 싶으시다면..)
5. 모델에 붙어있는 영어의 의미
- 모델에 뭐 coder / instruct / base / MoE가 붙어있는데 대체 뭔가 싶어서 조사하게 되어서 정리해두었다
5-1) Base 모델 (Foundation / Pretrained)
- 순수 학습만 된 모델
- 사람 말투/지시에 대한 이해 능력이 낮지만 그만큼 지식 압축도 + 생성 자유도가 높다
- 그래서 주로 RAG, 파인튜닝, 연구, 구조적 생성에 사용함
- e.g. Qwen2.5-72B
5-2) Instruct 모델
- 사람의 명령을 따르도록 RLHF/SFT 된 모델
- 질문 이해 능력이 좋고, 그로인해 안정성/대화품질이 높다
- 주로 챗봇, 코딩질문, Agent에 사용됨
- e.g. Qwen3-32B-Instruct
5-3) Coder 모델
- 코드 데이터로 추가 학습된 특화 모델
- 코드 특화 모델로 일반 대화는 Instruct보단 좀 딱딱하지만 코딩엔 월등한 성능을 보여줌
- IDE AI, 코드 생성 등에 주로 사용됨
- Qwen2.5-Coder
5-4) MoE 모델 (Mixture of Experts)
- 여러 개 작은 모델이 역할을 분담하는 구조
- input → Router → 전문가 모델 10개 중 3개(일부)만 활성화
- 파라미터가 엄청 크지만 실제 연산량은 적어서 성능 대비 효율이 좋은 편이다
- 그도 그럴 것이 모델이 여러개이고 그중에 필요한 일부만 활성화 하기 때문이다
- e.g. Qwen3.5-35B-A3B
6. 오픈소스 LLM들의 간단한 성능 리뷰

미리 알면 좋은 KV란?
- KV는 KV cache (Key-Value cache)를 의미하며, 쉽게 말해 GPU의 기억력되시겠다
- 이게 많을수록 답변 속도가 빨라진다
Qwen2.5-Coder-14B
- 코드 밖에 모르는 바보
- 대화가 답답하다
Qwen2.5-Coder-32B
- (14B보다 조금 더 똑똑한) 코드밖에 모르는 바보
Qwen2.5-72B (Base)
- A100 2장으로도 온전히 올라가지만 KV가 모자라서 성능이 제대로 안나와서 양자화가 필요했다
- 성능은 준수했음 (But, GPU RAM 부족으로 안정성은 부족)
Qwen2.5-72B-AWQ (instruct)
- KV를 좀 더 확보하고자 양자화된 모델을 구함
- 확실히 GPU RAM의 여유분이 KV가 되어서 그런지 답변 속도가 눈에 띄게 빨라졌고 이즈음부터 '그래도 좀 쓸만한데?' 라고 생각했음
⭐️ Qwen3-32B-Instruct (awq)
- 32B라고 무시했는데 2.5의 72B와 비슷하거나 좀 더 우월한 성능을 보여줬다
- 가령 같은 대답을 좀 더 빠르게 했다거나, 어려운 질문도 72B는 못했다면 얘는 한다거나 등등
- GPT-OSS-20B랑 같이 가장 괜찮다고 생각한 모델이었다
Qwen3.5-35B-A3B (MoE)
- 너무 최신의 것을 쓰면 호환이 안된다는 것을 배웠다...
- 컨테이너를 띄울 때부터 말썽이 좀 있었으며 오픈클로와의 호환성이 별로 좋지 못했음
- 나는 Qwen 페이지 모니터링하다가 35B 올라온 바로 다음날 적용해서 그럴 수도 있다 (지금은 안정화 되었을 수도?)
⭐️ GPT-OSS-20B
- Qwen3-32B-Instruct와 함께 가장 괜찮다고 생각했던 모델
- 답변 성능도 준수했으며 GPT에 익숙한 내게 비슷한 결의 답변과 flow로 대화할 수 있었다
- Qwen이 중국 모델이라는 약간의 찝찝함을 해소해준 모델이기도 함
7. 로컬 LLM 사용할 때 미리 알면 좋은 것들
- 이 부분은 생각날 때마다 추가하도록 하겠다
7-1) 모델은 갈아끼우기 쉬운 구조로 구축하면 편함
- 로컬 LLM은 보통 컨테이너를 사용해서 띄우게 된다
- 이때 모델을 갈아끼우기 좋은 형태로 두는 것이 좋다
- 예를들면 모델을 서빙하는 docker-compose.yml을 아래와 같이 구성해두고 .env 파일에 port랑 모델명을 전부 통일해두는 것이다
- 이렇게 하는 이유는 오픈클로가 LLM을 매번 하나씩 등록해야하는 번거로움이 있기 때문이다


- 이렇게 구축해두면 모델을 빠르게 돌아가면서 테스트하기 좋다
- 물론 이 방식으론 모델을 한개밖에 서빙 못한다는 단점이 있지만, 워낙 모델들이 무겁기도 했고, 빠르게 돌아가며 테스트 하는 목적이었기에 내 환경에 굉장히 적합했다
- 오픈클로에 모델을 매번 새롭게 등록하는게 귀찮아서 이렇게 했지만, 나중에 메인 모델 정해지면 그 모델은 따로 빼서 추가 등록하면 편하다
번외

- 이 글을 통해 그간 내가 결국 오픈클로보단 맥미니가 사고 싶어서 맥미니를 샀음을 솔직하게 인정하는 바이다 (고해성사)
- 그나마 다행인 것은 중고로 16GB, 1TB의 맥미니를 구해서 그냥 미디어 서버나 서브로 두고 써도 될 것 같다는 것 (안팔겠다는 의지)
- 결과적으로 나에겐 무용지물이지만, AI의 눈부신 발전속도를 몸으로 체감했다
- 실제로 주변에서도 많은 사람들이 오픈클로를 사용하고 있음
- 그리고 동시에 맥미니가 슬슬 중고로 쏟아져 나오고 있음 ㅎㅎ
- 그래도 언제나 새로운 것을 시도해보는 것은 정말 재밌다
'Dev > AI' 카테고리의 다른 글
| PII 모델 테스트, 성능 및 결과 (feat. Hugging Face) (0) | 2026.02.28 |
|---|---|
| 오픈클로(OpenClaw)에 로컬 LLM 연결하기 (feat. 비싼 API...) (0) | 2026.02.18 |
| 오픈클로(OpenClaw) 한방에 설치하기 (feat. 남는 PC에 설치하는 법) (0) | 2026.02.17 |
| LLM 토큰 아끼는 방법 (feat. GPT, Gemini, Claude) (0) | 2025.12.29 |
| GPT 모델 만들 때 반드시 체크 해제해야하는 것 (feat. 내 개인정보!!!) (0) | 2025.11.09 |