
늘 비용이 문제!!

오늘은 GPT나 Gemini같은 것들이 아니라 로컬에 LLM을 띄워서 직접 오픈클로에 연결해보겠다
이를 진행할 경우 API 사용요금이 일절 안나오기 때문에 비용절감 측면에서 기대가 된다 (서버 비용은 조상님이 내주시냐?!!)
일단 오늘 나는 GPU 서버를 별도로 준비했기 때문에 여기에 LLM을 띄워서 진행해볼 예정이다
ps.
- 참고로 오늘 사용한 오픈클로 서버는 M1 맥미니(MacOS)이다
- 나처럼 별도의 GPU가 아닌 하나의 맥미니에서 다 해결하시는 경우 3번(오픈클로에 로컬 LLM 연결하기)만 보시면 될듯하다
26.03.20 업데이트
- 오픈클로 한달 후기이자 나(만)의 결론
- 맥미니는 사지 마시라!!! ㅠㅠ
https://ratatou2.tistory.com/358
오픈클로(OpenClaw) 한달 후기 (feat. 로컬 LLM vs 상용 AI API)
(침몰한) 프로젝트 몰티저스이번 글은 나의 오픈클로 한달 체험기가 되겠다나는 한달 조금 넘는 시간동안 이것저것 실험해보았고 나만의 결론을 낼 수 있었다그리고 누군가에게 도움이 되고자
ratatou2.tistory.com
1. (선택) VPN 세팅하기
- 일단 이 부분은 선택사항이다
- 나는 GPU 서버가 있고, 외부로부터 완전하게 차단하기 위해서 이와 같이 진행했다
- 특히 오픈클로가 설치되어있는 서버와 로컬 LLM을 띄워둔 서버가 동일하다면 VPN은 더더욱 필요없다
- 나는 두 서버가 따로 존재했기에 보안을 위해서 오로지 VPN만을 통해서 GPU서버에 접근할 수 있도록 하였음
- 아래 내용은 간략히 GPU 서버에 VPN을 구축한 내용이다
<< 기본 골조 >>
- 오픈클로가 VPN 터널로만 A100의 vLLM(8002 등)에 접속하는 것이 목표이다
A100 GPU 서버 = WireGuard 서버 (VPN 터널 끝점, 10.66.66.1)
몰트봇/맥미니 = WireGuard 클라이언트 (10.66.66.2)
<< WireGuard 실행 - GPU 서버 >>
sudo wg-quick up wg0
# 부팅 시 자동 기동
sudo systemctl enable wg-quick@wg0<< 방화벽 등록 >>
- Wireguard의 기본 포트인 51820를 'UDP'로 열어야함을 잊지말자
sudo ufw allow 51820/udp
sudo ufw allow in on wg0
sudo ufw allow out on
wg0sudo ufw reload<< VPN 설정 - GPU 서버 & 오픈클로 서버 >>
- GPU 서버 /etc/wireguard/wg0.conf
[Interface]
Address = 10.66.66.1/24
ListenPort = 51820
PrivateKey = <GPU 서버 Privatekey>
# Mac Mini (M1)
[Peer]
PublicKey = <맥미니 Publickey>
AllowedIPs = 10.66.66.2/32- 맥미니 wireguard 설정
[Interface]
PrivateKey = <맥미니 PrivateKey>
ListenPort = 51820
Address = 10.66.66.2/24
[Peer]
PublicKey = <GPU 서버 PublicKey>
AllowedIPs = 10.66.66.0/24 # 이 부분이 핵심!!! (0.0.0.0/24로 하면 모든 네트워크 통신이 VPN을 통해 넘어가서 상대 서버에서 인터넷을 열어두지 않았다면 차단된다!!)
Endpoint = <GPU 서버 IP>:<GPU 서버의 wireguard 포트>
PersistentKeepalive = 25- 주의할 점은 맥미니(오픈클로 서버)에서 AllowedIPs를 잘못 설정하면 Telegram이나 외부 인터넷(e.g. 검색)등이 동작하지 않을 수 있으니 잘 확인해보자
- 나 같은 경우엔 GPU 서버를 외부에서 아예 차단했어서 VPN을 통해 인터넷 하는 것들이 불가능 하였음
<< 연결 테스트 >>
- 오픈클로 서버에서 GPU 서버로 ping을 보내봐서 잘 되면 문제 없다
ping 10.66.66.1<< 번외 >>
- 혹시나 Docker에서 GPU 인식을 못한다면 아래 포스팅 참조
https://ratatou2.tistory.com/351
Docker에 nvidia 권한 주기 (feat. Unable to locate package nvidia-container-toolkit)
아니 왜 비싼거 줘도 싫다는건데;;오픈클로 만지작 대느라 GPU 서버의 Docker에서 GPU 인식을 못했다Docker에서 GPU 갖다 쓸 수 있게 해보자1. 에러 원인- GPU 서버에서 Docker로 LLM 띄우려니 에러발생- 확
ratatou2.tistory.com
- VPN 구축에 대한 자세한 내용은 아래 포스팅 참조
https://ratatou2.tistory.com/287
나만의 VPN 서버 만들기 (feat. WireGuard 적용하기)
쉴 틈이 없는 나의 서버..주말에 친구랑 같이 카페에서 각자 일하고 있는데 핫스팟을 켜달라는 것이다...아니 갑자기...??회사 일을 지금 해야할 것 같은데 카페라 공개 IP로는 작업하기 어렵다는
ratatou2.tistory.com
- 참고로 나는 VPN을 설정하고 진행했기에 아래 두 IP를 사용하였고 각자 상황에 맞게 치환해서 쓰시면 된다
(e.g. 오픈클로 컨테이너 IP / LLM 컨테이너 IP)
10.66.66.1 - GPU 서버 IP
10.66.66.2 - 오픈클로 서버 IP
2. GPU 서버에 로컬 LLM 세팅하기
- 확실히 로컬 LLM을 구축하는게 좀 번거로운게 많았다..
2-1) 허깅페이스(HuggingFace) 및 테스트 모델 소개
- 우선 허깅페이스에서 오픈소스 LLM을 다운받아주었다
(허깅 페이스는 기계 학습 모델을 구축, 배포 및 교육하기 위한 도구와 리소스를 개발하는 프랑스계 미국 회사이자 오픈 소스 커뮤니티라고 한다 - 출처:위키)
Hugging Face – The AI community building the future.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
- 테스트 했던 모델 목록은 아래와 같다
- qwen2.5-72b-awq
- qwen2.5-72b-fp16 (양자화 안한 순수 모델은 돌리기 너무 버거웠다...)
- qwen2.5-coder-14b
- qwen2.5-coder-32b
- 아래 사진은 각 모델들을 다운로드 받아 디렉토리에 넣어둔 것이다 (서버에 다운받는 방법도 아래에서 소개할 예정!)

- 이번 포스팅에서 예시를 들 모델은 qwen2.5-72b-awq이다
https://huggingface.co/Qwen/Qwen2.5-72B-Instruct-AWQ/tree/main
Qwen/Qwen2.5-72B-Instruct-AWQ at main
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co


2-2) 허깅페이스(HuggingFace) 라이브러리 설치 및 LLM 모델 다운로드
- 맥미니처럼 모니터 연결하고 볼 수 있는 환경이라면 직접 다운로드 해서 폴더 지정해도 된다
- 다만 나같은 경우엔 물리적 서버에 접근할 수 없어 CLI를 사용해야했기에 huggingface_hub 라이브러리를 쓸 예정이다
- pip를 통해 설치 진행
pip install huggingface_hub- 다운로드 명령어
# 템플릿
hf download <다운로드할 모델 ID> \
--local-dir <저장 경로>
# 예시
hf download Qwen/Qwen2.5-Coder-14B-Instruct-AWQ \
--local-dir /models/qwen2.5-coder-14b- 다운로드할 모델 ID 확인 방법은 아래 접은글 참조
- 우선 원하는 LLM 모델을 찾았다면 'Use this model'을 선택한다

- 그리고 Transformers나 vLLM 등 아무거나 눌러보면 밑에 줄 친 것처럼 우리가 필요한 모델 ID를 확인할 수 있다

- 명령어 실행하면 아래처럼 모델을 다운받게 된다

2-3) LLM 모델 띄우기
- Docker를 사용해서 띄웠고 아래가 docker-compose.yml, .env, 스크립트들 예시이다
- 모델따라 다를테니 참고정도만..!
<< docker-compose.yml >>
- docker-compose.yml에 모델을 여러개 준비하고 돌려가며 테스트 해보았다
services:
vllm-14b:
image: vllm/vllm-openai:latest
container_name: vllm-14b
gpus: all
environment:
NVIDIA_VISIBLE_DEVICES: ${VLLM_14B_GPU_DEVICES:-0}
CUDA_VISIBLE_DEVICES: ${VLLM_14B_GPU_DEVICES:-0}
volumes:
- ${MODELS_DIR:-/models}:/models
ports:
- "${VLLM_14B_BIND_IP:-127.0.0.1}:${VLLM_14B_PORT:-8001}:8000"
command:
- --model
- ${VLLM_14B_MODEL_PATH:-/models/qwen2.5-coder-14b}
- --quantization
- ${VLLM_14B_QUANTIZATION:-awq}
- --max-model-len
- ${VLLM_14B_MAX_MODEL_LEN:-8192}
- --gpu-memory-utilization
- ${VLLM_14B_GPU_MEMORY_UTILIZATION:-0.85}
- --host
- 0.0.0.0
- --port
- "8000"
- --enable-auto-tool-choice
- --tool-call-parser
- hermes
restart: unless-stopped
vllm-32b:
image: vllm/vllm-openai:latest
container_name: vllm-32b-coder
gpus: all
profiles: ["multi-model"]
environment:
NVIDIA_VISIBLE_DEVICES: ${VLLM_32B_GPU_DEVICES:-0,1}
CUDA_VISIBLE_DEVICES: ${VLLM_32B_GPU_DEVICES:-0,1}
volumes:
- ${MODELS_DIR:-/models}:/models
ports:
- "${VLLM_32B_BIND_IP:-127.0.0.1}:${VLLM_32B_PORT:-8002}:8000"
command:
- --model
- ${VLLM_32B_MODEL_PATH:-/models/qwen2.5-coder-32b}
- --served-model-name
- ${VLLM_32B_SERVED_MODEL_NAME:-qwen32b}
- --quantization
- ${VLLM_32B_QUANTIZATION:-awq_marlin}
- --tensor-parallel-size
- ${VLLM_32B_TENSOR_PARALLEL_SIZE:-2}
- --max-model-len
- ${VLLM_32B_MAX_MODEL_LEN:-32768}
- --max-num-batched-tokens
- ${VLLM_32B_MAX_NUM_BATCHED_TOKENS:-4096}
- --max-num-seqs
- ${VLLM_32B_MAX_NUM_SEQS:-32}
- --gpu-memory-utilization
- ${VLLM_32B_GPU_MEMORY_UTILIZATION:-0.95}
- --host
- 0.0.0.0
- --port
- "8000"
- --enable-auto-tool-choice
- --tool-call-parser
- hermes
restart: unless-stopped
vllm-32b-instruct:
image: vllm/vllm-openai:latest
container_name: vllm-32b-instruct
gpus: all
profiles: ["multi-model"]
environment:
NVIDIA_VISIBLE_DEVICES: ${VLLM_32B_INSTRUCT_GPU_DEVICES:-0,1}
CUDA_VISIBLE_DEVICES: ${VLLM_32B_INSTRUCT_GPU_DEVICES:-0,1}
volumes:
- ${MODELS_DIR:-/models}:/models
ports:
- "${VLLM_32B_INSTRUCT_BIND_IP:-127.0.0.1}:${VLLM_32B_INSTRUCT_PORT:-8004}:8000"
command:
- --model
- ${VLLM_32B_INSTRUCT_MODEL_PATH:-/models/qwen2.5-32b-instruct}
- --served-model-name
- ${VLLM_32B_INSTRUCT_SERVED_MODEL_NAME:-qwen32b-instruct}
- --quantization
- ${VLLM_32B_INSTRUCT_QUANTIZATION:-awq_marlin}
- --tensor-parallel-size
- ${VLLM_32B_INSTRUCT_TENSOR_PARALLEL_SIZE:-2}
- --max-model-len
- ${VLLM_32B_INSTRUCT_MAX_MODEL_LEN:-32768}
- --max-num-batched-tokens
- ${VLLM_32B_INSTRUCT_MAX_NUM_BATCHED_TOKENS:-4096}
- --max-num-seqs
- ${VLLM_32B_INSTRUCT_MAX_NUM_SEQS:-32}
- --gpu-memory-utilization
- ${VLLM_32B_INSTRUCT_GPU_MEMORY_UTILIZATION:-0.95}
- --host
- 0.0.0.0
- --port
- "8000"
- --enable-auto-tool-choice
- --tool-call-parser
- hermes
restart: unless-stopped
vllm-72b:
image: vllm/vllm-openai:latest
container_name: vllm-72b
gpus: all
profiles: ["multi-model"]
environment:
NVIDIA_VISIBLE_DEVICES: ${VLLM_72B_GPU_DEVICES:-0,1}
CUDA_VISIBLE_DEVICES: ${VLLM_72B_GPU_DEVICES:-0,1}
volumes:
- ${MODELS_DIR:-/models}:/models
ports:
- "${VLLM_72B_BIND_IP:-127.0.0.1}:${VLLM_72B_PORT:-8003}:8000"
command:
- --model
- ${VLLM_72B_MODEL_PATH:-/models/qwen2.5-72b}
- --served-model-name
- ${VLLM_72B_SERVED_MODEL_NAME:-qwen72b}
- --quantization
- ${VLLM_72B_QUANTIZATION:-awq_marlin}
- --tensor-parallel-size
- ${VLLM_72B_TENSOR_PARALLEL_SIZE:-2}
- --max-model-len
- ${VLLM_72B_MAX_MODEL_LEN:-32768}
- --max-num-batched-tokens
- ${VLLM_72B_MAX_NUM_BATCHED_TOKENS:-4096}
- --max-num-seqs
- ${VLLM_72B_MAX_NUM_SEQS:-32}
- --gpu-memory-utilization
- ${VLLM_72B_GPU_MEMORY_UTILIZATION:-0.95}
- --host
- 0.0.0.0
- --port
- "8000"
- --enable-auto-tool-choice
- --tool-call-parser
- hermes
restart: unless-stopped<< .env >>
MODELS_DIR=./models
VLLM_14B_BIND_IP=127.0.0.1
VLLM_14B_PORT=8001
VLLM_14B_GPU_DEVICES=0
VLLM_14B_MODEL_PATH=/models/qwen2.5-coder-14b
VLLM_14B_MODEL_NAME=/models/qwen2.5-coder-14b
VLLM_14B_QUANTIZATION=awq
VLLM_14B_MAX_MODEL_LEN=4096
VLLM_14B_GPU_MEMORY_UTILIZATION=0.7
VLLM_32B_BIND_IP=0.0.0.0
VLLM_32B_PORT=8002
VLLM_32B_GPU_DEVICES=0,1
VLLM_32B_MODEL_PATH=/models/qwen2.5-coder-32b
VLLM_32B_MODEL_NAME=/models/qwen2.5-coder-32b
VLLM_32B_SERVED_MODEL_NAME=qwen32b
VLLM_32B_QUANTIZATION=awq_marlin
VLLM_32B_TENSOR_PARALLEL_SIZE=2
VLLM_32B_MAX_MODEL_LEN=32768
# 0.95 = more VRAM for KV cache (model+KV); OOM 시 0.90으로 낮추기
VLLM_32B_GPU_MEMORY_UTILIZATION=0.95
# 4096 = better single-request token latency; 32 = less preemption, more KV per request
VLLM_32B_MAX_NUM_BATCHED_TOKENS=4096
VLLM_32B_MAX_NUM_SEQS=32<< Script >>
- 모델별로 스크립트도 만들어서 로그 & 편리함을 챙기고자 했음
#!/usr/bin/env bash
##################
# start-14b.sh
##################
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")/.." && pwd)"
ENV_FILE="$ROOT_DIR/.env"
# shellcheck source=scripts/lib/common.sh
source "$ROOT_DIR/scripts/lib/common.sh"
ensure_env
"$ROOT_DIR/scripts/preflight.sh" || true
echo "[INFO] vLLM 14B 단일 모델 실행"
docker compose --env-file "$ENV_FILE" -f "$ROOT_DIR/docker-compose.yml" up -d vllm-14b
echo "[INFO] 완료: http://127.0.0.1:${VLLM_14B_PORT:-8001}/v1/models"#!/usr/bin/env bash
##################
# start-32b.sh
##################
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")/.." && pwd)"
ENV_FILE="$ROOT_DIR/.env"
# shellcheck source=scripts/lib/common.sh
source "$ROOT_DIR/scripts/lib/common.sh"
ensure_env
"$ROOT_DIR/scripts/preflight.sh" || true
stop_14b_if_running
echo "[INFO] vLLM 32B만 실행 (GPU ${VLLM_32B_GPU_DEVICES:-0,1}, TP=2)"
docker compose --profile multi-model --env-file "$ENV_FILE" -f "$ROOT_DIR/docker-compose.yml" up -d vllm-32b
echo "[INFO] 완료: 32B http://127.0.0.1:${VLLM_32B_PORT:-8002}/v1/models"#!/usr/bin/env bash
##################
# start-72b.sh
##################
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")/.." && pwd)"
ENV_FILE="$ROOT_DIR/.env"
# shellcheck source=scripts/lib/common.sh
source "$ROOT_DIR/scripts/lib/common.sh"
ensure_env
"$ROOT_DIR/scripts/preflight.sh" || true
stop_14b_if_running
echo "[INFO] vLLM 72B만 실행 (GPU ${VLLM_72B_GPU_DEVICES:-0,1})"
docker compose --profile multi-model --env-file "$ENV_FILE" -f "$ROOT_DIR/docker-compose.yml" up -d vllm-72b
echo "[INFO] 완료: 72B http://127.0.0.1:${VLLM_72B_PORT:-8003}/v1/models"3. 오픈클로에 로컬 LLM 연결하기
- (나의 환경에서는) 연결 테스트는 VPN을 켜고 아래 명령어를 통해 진행
- 나는 GPU 서버를 VPN 상 10.66.66.1로 세팅해두었기에 아래로 요청을 보낸 것이다
- 여러분의 LLM 컨테이너가 같은 맥미니에 떠있다면 해당 컨테이너 IP로 요청을 보내면 될 것이다
(아래 명령어에 대한 응답 형식이 규격화 되어있었음. 궁금해서 찾아보니 은 vLLM이 OpenAI API 호환 모드로 떠있어서 그렇다고 한다)
curl -s http://10.66.66.1:8002/v1/models- GPU 서버에 응답 세팅해둔대로 현재 모델이 무엇인지 경로 등의 정보를 잘 전달하고 있다

➜ ~ curl http://10.66.66.1:8002/v1/models
{"object":"list","data":[{"id":"qwen32b","object":"model","created":1771397073,"owned_by":"vllm","root":"/models/qwen2.5-coder-32b","parent":null,"max_model_len":32768,"permission":[{"id":"modelperm-ac613a8f56fcba7f","object":"model_permission","created":1771397073,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}%- 이제 LLM을 추가할텐데 각자 상황에 맞춰 아래 두가지 명령어 중 하나를 선택해서 진행하면 된다
(위에서 요청으로 받은 id, 즉 LLM 모델명을 잘 기억하자)
# 오픈클로 초기 세팅 (진짜 처음 시작하는 경우)
openclaw onboard
# 오픈클로 어느정도 세팅 되어있고 LLM만 추가하는 경우 (둘중 하나)
openclaw providers add
openclaw models add
- 우리는 로컬 LLM으로 진행할거니까 vLLM으로 진행했다

- 이후엔 아래 순서대로 고르면 된다
Base URL - VPN이나 Docker로 세팅된 타 서버 IP/컨테이너 주소를 넣으면 된다
API key - 아무거나 넣으면 된다 (나는 dummy)로 넣었다
vLLM model - 이거는 curl 요청 보내서 GPU서버/LLM컨테이너가 응답으로 보내는 LLM ID를 적으면 된다
Default model - 방금 등록한걸로 설정해주었다
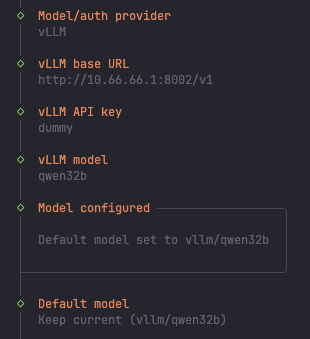
- 이후엔 전부 default로 설정했다

- 인증방식은 토큰 방식이 더 안전하니까 토큰 선택
| 방식 | 설명 | 추천도 |
| Token | API key 방식 인증 | 추천 |
| Password | 단일 비밀번호 | 덜 안전 |
- 여기까지 진행했으면 자주 쓰는 SNS도 연결하면 된다 (여기서는 텔레그램으로 진행)
- 텔레그램 선택해주고
- 봇 API 입력해주고
- 채널 더 추가해줄거 없으면 종료하고 텔레그램 DM 정책은 pairing 선택

- 이후에 텔레그램 봇 채널에 아무 메세지나 보내면 아래처럼 응답이 온다
- 맨 밑의 한줄을 오픈클로 있는 터미널에 입력해주면 페어링이 됨

- 그리고 채팅하면 대화가 잘 된다

- 근데 로컬 LLM 모델 전반이 문맥을 이해 못하고 답변도 잘 못해서 좀 튜닝이 필요할듯 싶다
- 예를들면 Gemini API (2.5-flash) 쓸 때는 '해당 디렉토리에 뭐가 있는지 알아와' 하면 '~~~가 있습니다' 이렇게 되는데, 로컬 LLM은 알아보겠다고 하고 그대로 감감무소식... 아무래도 어느 세팅이 잘못된듯 싶다

'Dev > AI' 카테고리의 다른 글
| 오픈클로(OpenClaw) 한달 후기 (feat. 로컬 LLM vs 상용 AI API) (0) | 2026.03.20 |
|---|---|
| PII 모델 테스트, 성능 및 결과 (feat. Hugging Face) (0) | 2026.02.28 |
| 오픈클로(OpenClaw) 한방에 설치하기 (feat. 남는 PC에 설치하는 법) (0) | 2026.02.17 |
| LLM 토큰 아끼는 방법 (feat. GPT, Gemini, Claude) (0) | 2025.12.29 |
| GPT 모델 만들 때 반드시 체크 해제해야하는 것 (feat. 내 개인정보!!!) (0) | 2025.11.09 |