
쿱네 튜닝 최종장!

미루고 미뤘던 쿱네 튜닝의 최종장에 접어들었다
마지막 포스팅에 적어뒀던 것처럼 오늘은 3가지를 목표로 두고 있다

일단 결론부터 말하면 실패했다
정확히는 반만 실패했다
요인은 k6 부하테스트를 진행하는 서버의 문제(부하를 주는 쪽)였음
세팅 과정은 지루하니까 간단하게 어떤 방식으로 진행했고, 무엇을 개선했고, 어떻게 접근했는지 튜닝의 결과값을 보며 진행해보겠다
0. 지난 시간
- 지난 포스팅은 솔직히 '이론' 중점이었다고 생각한다
- 어떤 것을 썼고 왜 그렇게 썼는지 그리고 결과가 어땠는지 결과에 대한 분석?
- 오늘은 지난번에 해보려고 했던 것을 전부 완성한 결과니까 결과 지향적으로 접근해보려고 한다
1. 첫번째 실험
- 우선 지난번 실험은 ingress-nginx를 설치해서 nginx 분산처리 때와 똑같은 구조를 만들고자 했다
- 하나의 진입로(ingress-nginx), 노동자들(app pod들)
- 처음엔 테스트로 app 노드가 세개니까 app 백엔드에 해당하는 pod를 세개만 띄웠다
- 그리고 요청 테스트를 시도하니까 그라파나의 CPU 그래프가 튀면서 정상적으로 각자 요청을 받고 있음을 확인할 수 있었다
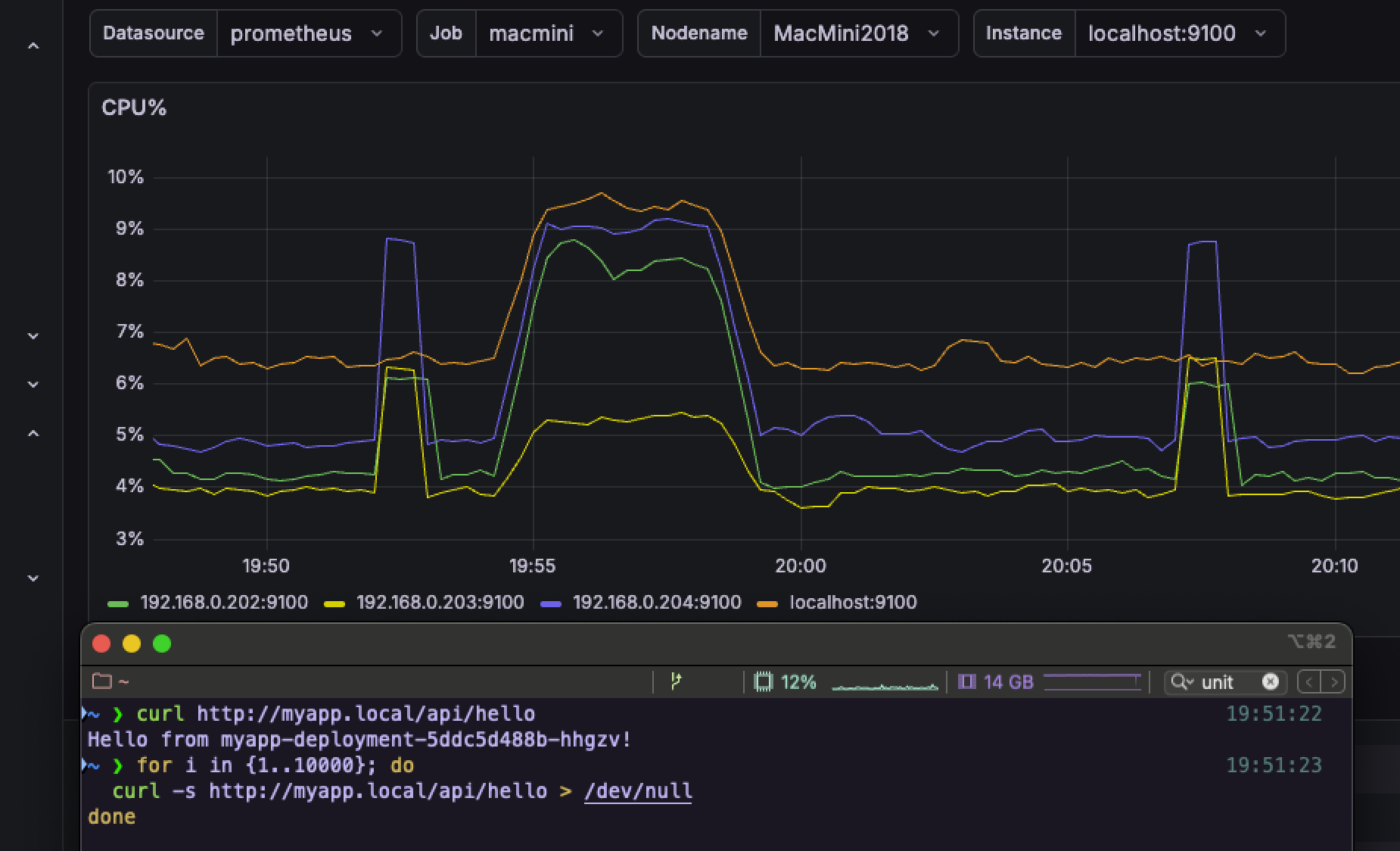
- 정상적으로 작동하는 것을 확인했으니 맛보기로 pod 갯수를 20개로 늘렸다
- 실제로 초기엔 3개로만 시작하다가 CPU 사용률이 165%를 찍더니, 20개까지 늘린 모습을 볼 수 있었음

- 근데 그러고도 CPU 사용률이 281%;;
- 그리고는 바로 터지기 시작 (나중에 알고보니 k6 부하테스트를 걸어주는 서버가 병목 지점이었다)

- 터지는 순간엔 요청이 제대로 들어간게 아니고, 요청이 안들어가서 서버가 일을 안하기 때문에 그래프도 휘청거리기 시작
(정확히는 k6 부하를 걸어주는 서버에서 TCP 연결 실패로 인한 병목 탓이었다)
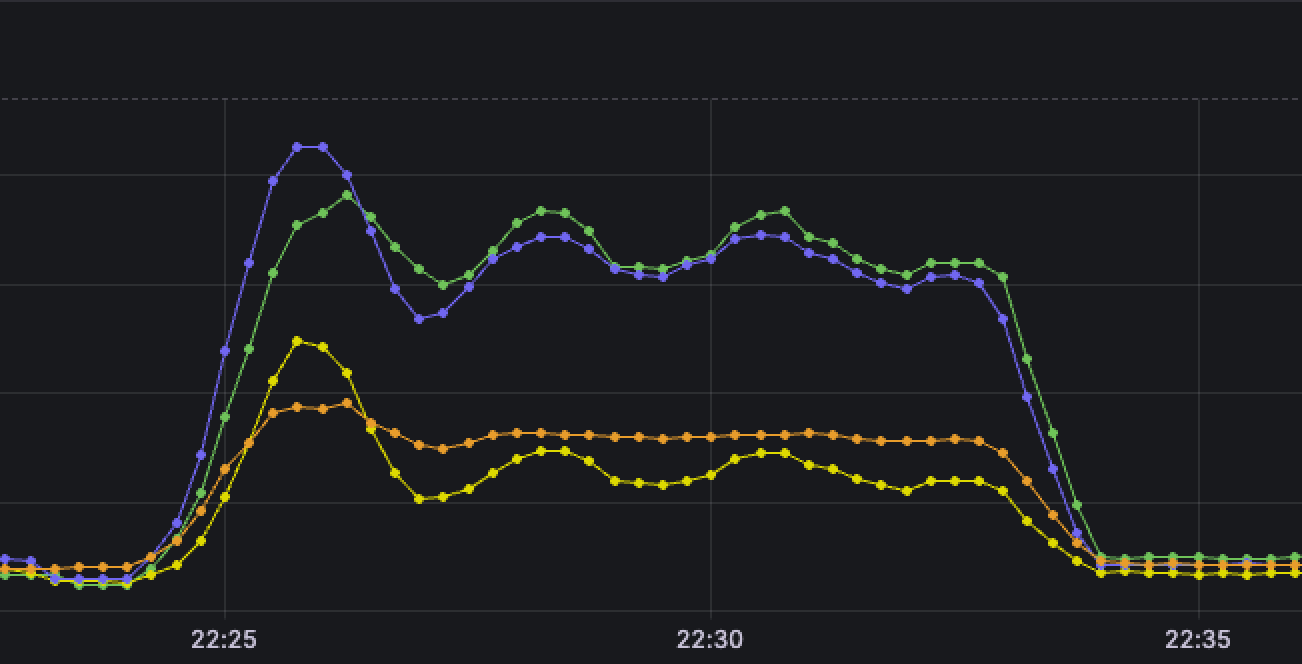
- 지속적으로 요청이 들어오고 있는 상황이라면 리소스가 쉴 틈은 없으므로 전체적인 평균은 아래 사진처럼 수평 or 우상향이 되어야한다
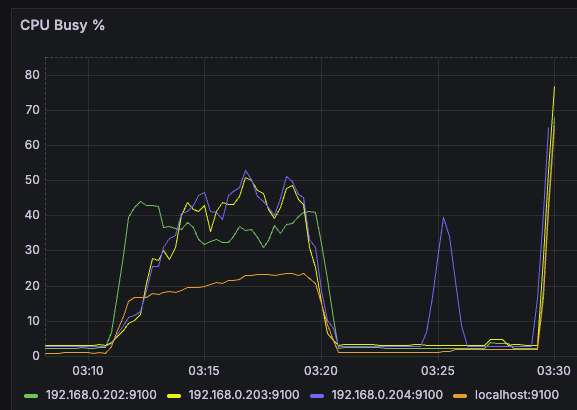
- 근데 아래 그래프를 보면 전체적으로 (요청을 받고 있는 서버까지) 떨어지는 것을 볼 수 있다

- 더군다나 app 서버 3대 중 (그나마) 제일 여유로운 스펙인 LG 데스크탑은 CPU 사용률 여유로운데 나머지는 널뛰기 시작
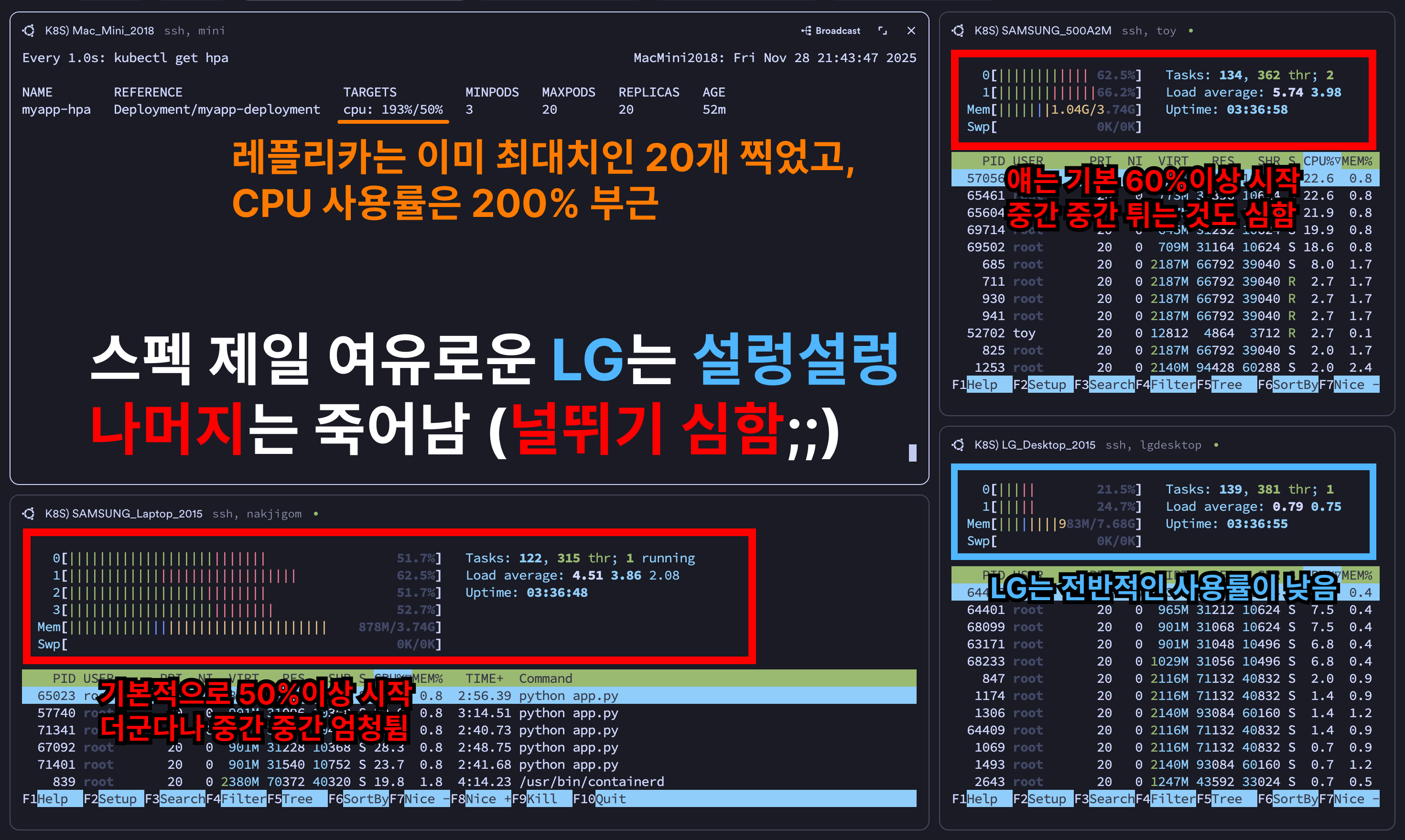
- 안그래도 성능 낮아서 기본 CPU 점유율 50% 깔고 시작인데 요청도 일부 씹히니까 날뛴 것으로 추측
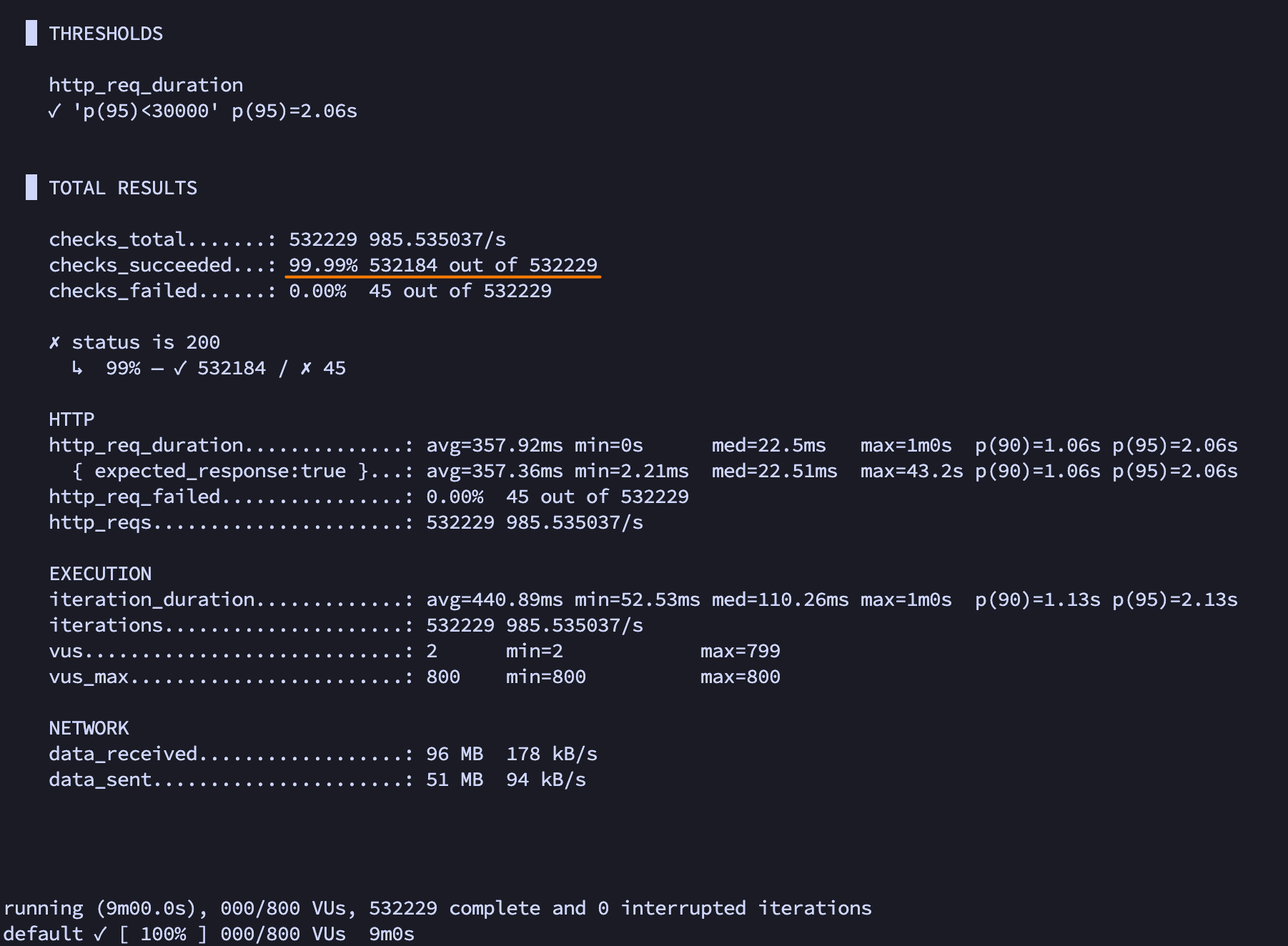
- 그 와중에 씹힌 것들은 실패로 안쳐서 k6 부하테스트는 성능이 99% ㅋㅋㅋ...

- 안되겠다 싶어서 레플리카를 200개까지 늘려보고자 했음
- 바로 냅다 적용

- 부하테스트 시작하자마자 24개 찍고 시작

- 이후 곧 내가 세팅한 CPU 사용률이 50%에 머무를 때까지 레플리카 증식
- 94개째에서 50% 유지 되었고 이후 pod는 늘어나지 않았다

- 물론 터지는 것은 여전해서 이 부분은 이해가 안가기 시작
(이후에 이해가 됨, 맨 밑에 포스팅)

- 여전히 부하테스트도 이상함
- 이게 어떻게 99%?

2. 두번째 실험
- 이번에는 맥미니에만 ingress-nginx를 띄워서 nginx 분산처리 때와 똑같은 구조를 만들고자 했다
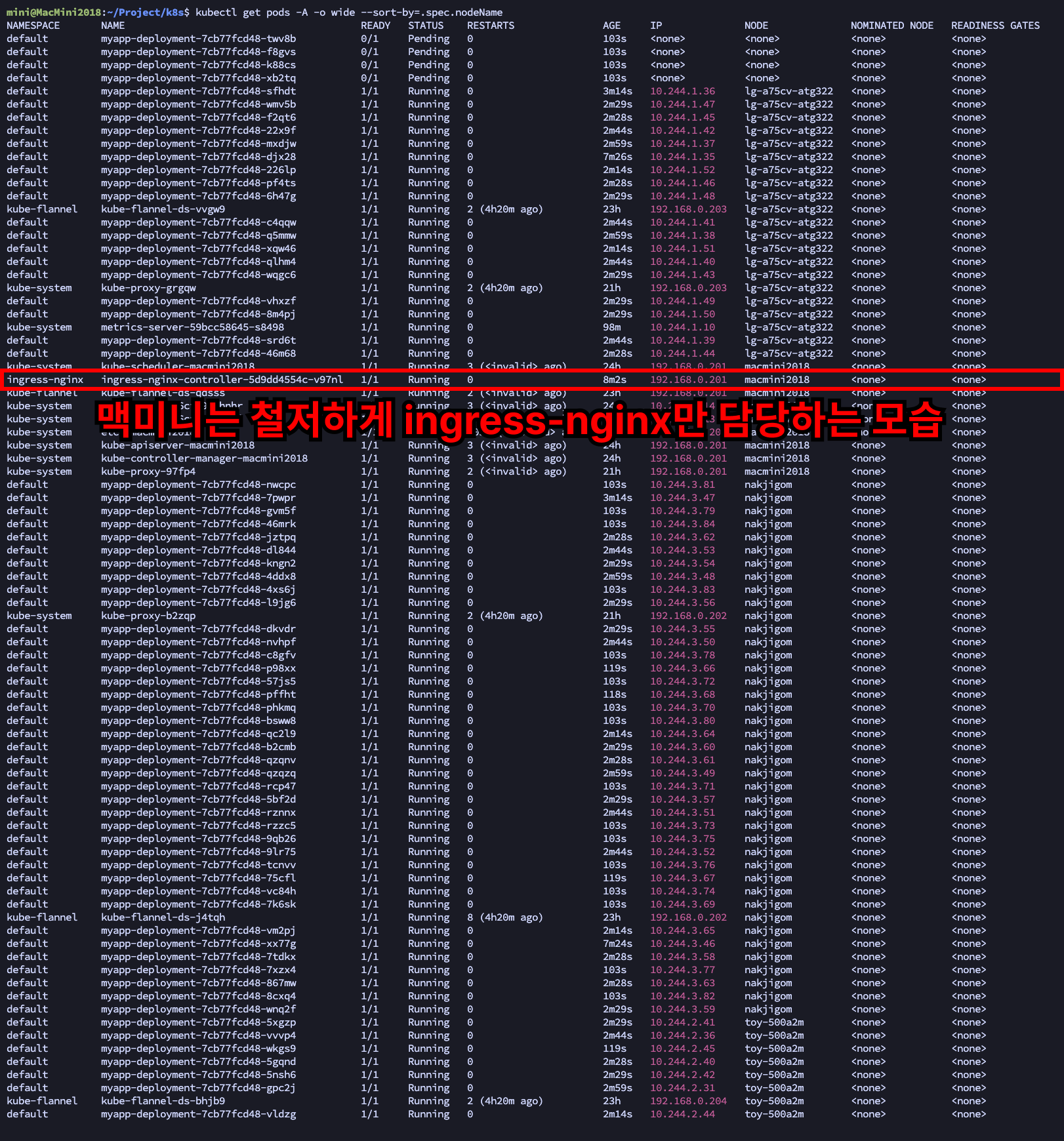
- 근데 그렇다고 뭐 LG 데스크탑이 더 많은 파드(app 파드)를 가져가고 이런 것은 없었다
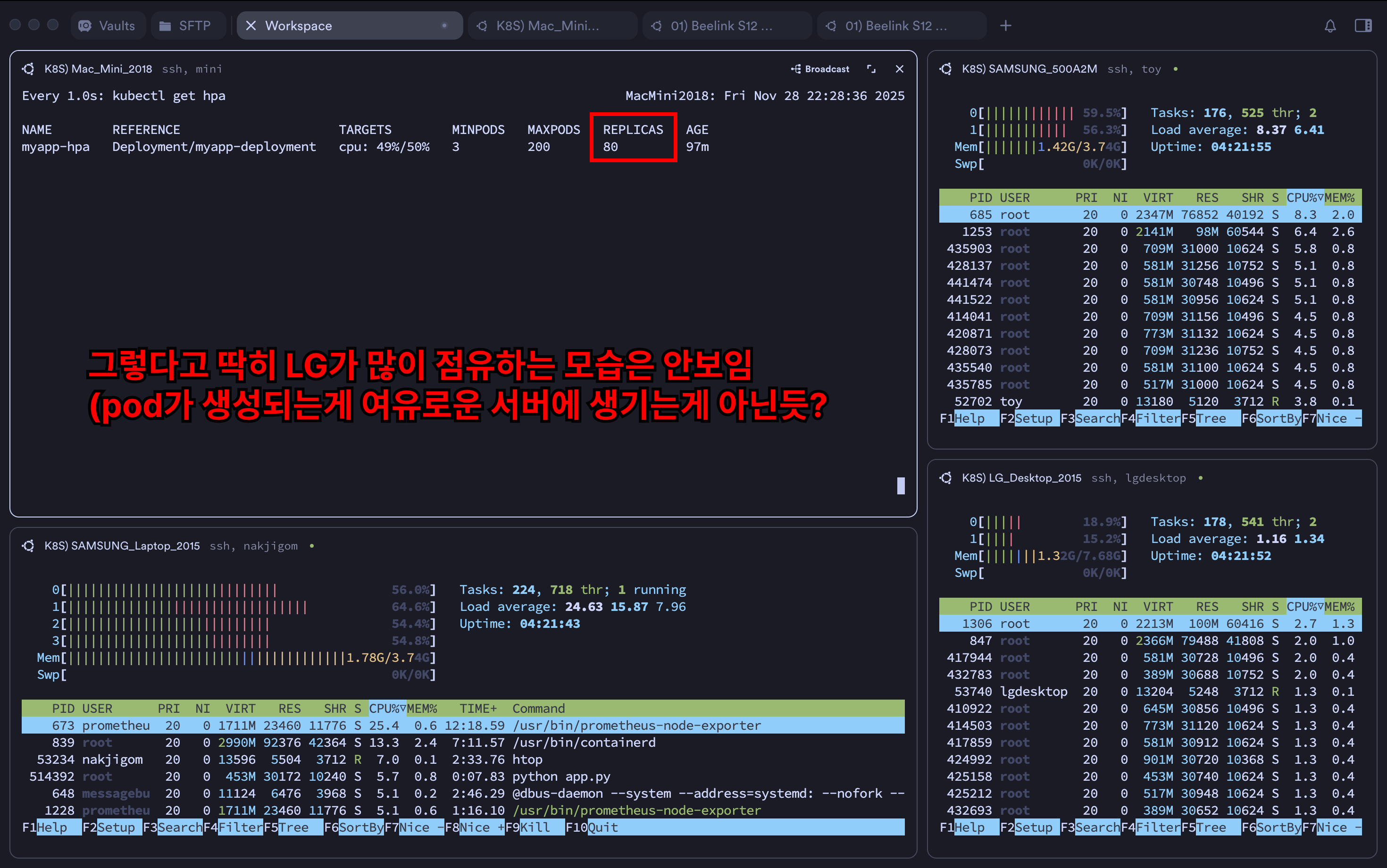
- 아마 pod를 생성하는 기준이 서버의 성능 우위나, 리소스의 여유가 아닌 듯하다
- 찾아보니 서버마다 스코어(점수)를 매겨놓고 그런 것들로 판단해서 배정한다고...
- 근데 확실히 터지는 빈도가 엄청 줄긴했다

- 전과달리 CPU 사용률도 '전보단' 균일하게 유지되는 모습이다
- 이제는 의미없어진 k6 부하테스트는 여전히 99%
3. 세번째 실험
- 이제는 모든 노드(서버)에 ingress-nginx를 하나씩 띄우고, LB(LoadBalancer)로 묶어서 하나의 IP처럼 사용하는 것이다
- 이 때 LB를 MetalLB를 사용했고, 내부망에 VIP라는, 대표격의 IP를 할당함으로써 4대의 서버를 한대처럼 사용할 수 있게 하였다
- 여기도 수많은 삽질이 있었지만 오늘은 결과부터 보도록하겠다
- 일단 그래프를 보다시피 전보다 점진적으로 부하가 늘어나긴 하지만, 중간중간 들쑥날쑥하다
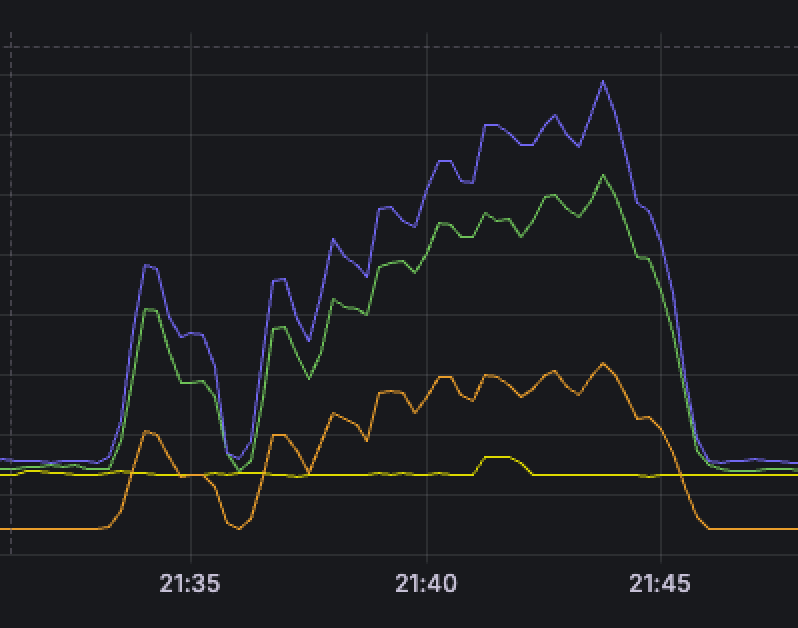
- 얘도 엄청 많이 터지기 때문이다...

- 그럼에도 또 터짐...
- 93%까지 떨어지긴 했지만 요청도 처리 다 못했으므로 이 또한 유의미하다고 보기 어려웠다

4. 내내 터진 이유
- 사실 이게 이번 실험의 핵심인데 터진 이유는 사실 k6 부하를 보내는 쪽의 '포트 부족' 때문이다
- 쉽게 말해 k6 부하테스트를 걸던 n100 홈서버가 '나약했기 때문'이다

- 로그는 정확히 아래 내용임
# k6를 실행한 ‘요청 보내는 머신’이 먼저 터진 것
# (= OS가 새 TCP 연결을 만들 포트(port)를 더 이상 할당 못함)
dial tcp 192.168.0.240:80: connect: cannot assign requested address- 즉 부하를 일으킨 쪽이 테스트 하는 쪽보다 먼저 죽었고, 그 이유는 스펙의 한계 때문이다
- 필요한 새로운 연결(커넥션)을 만들지 못해서 요청이 가야할 곳을 찾지 못한 셈 (연결된 통로가 없으니까)
근데 k6 부하테스트 성공률은 높은 이유?
- 그건 이제 k6는 요청을 보내기 전에 실패한 것을 http_req_duration 통계에 제대로 포함하지 않기 때문이다
- 즉, 보내기 전에 실패한건 실패한거로 안친다는 의미
- 결국 미니 PC에서 클러스터쪽으로 테스트를 보냈는데? 스펙 한계상 포트에 부하가 와서 새롭게 연결을 추가 생성 못했고 그래서 문제가 생겼었다는 것
그럼 이전 nginx 분산 테스트 때는 왜 문제가 없었는가?
- 이제 그 당시에는 nginx를 쓰면서 기존의 연결들을 '재사용'했었다
- 즉, 기존의 연결을 새로 생성할 필요가 없었고 그렇게 간당간당한 범위 내에서 끝낼 수 있었던 것
한줄요약
- 예전 nginx는 '연결이 안정적으로 재사용되는 부하'
- 이번 K8s는 'TCP 연결을 미친 듯이 새로 만드는 부하'
개선방법
- 이 상태에서 k6 부하를 걸어서 쿠버네티스 분산 시스템을 한계까지 제대로 몰아붙이려면?
- 일단 부하 테스트도 분산처리해서 부하를 줘야한다
- 즉, A PC와 B PC 둘로 나눠서 부하 테스트를 해야한다는 의미
- 이 부분은 의견이 필요해서 GPT에게 물어보니 대충 내가 가진 별도의 PC 두 대(AMD 5600x, M3 맥북 에어)를 사용하면 될 것이라는 의견을 받았다
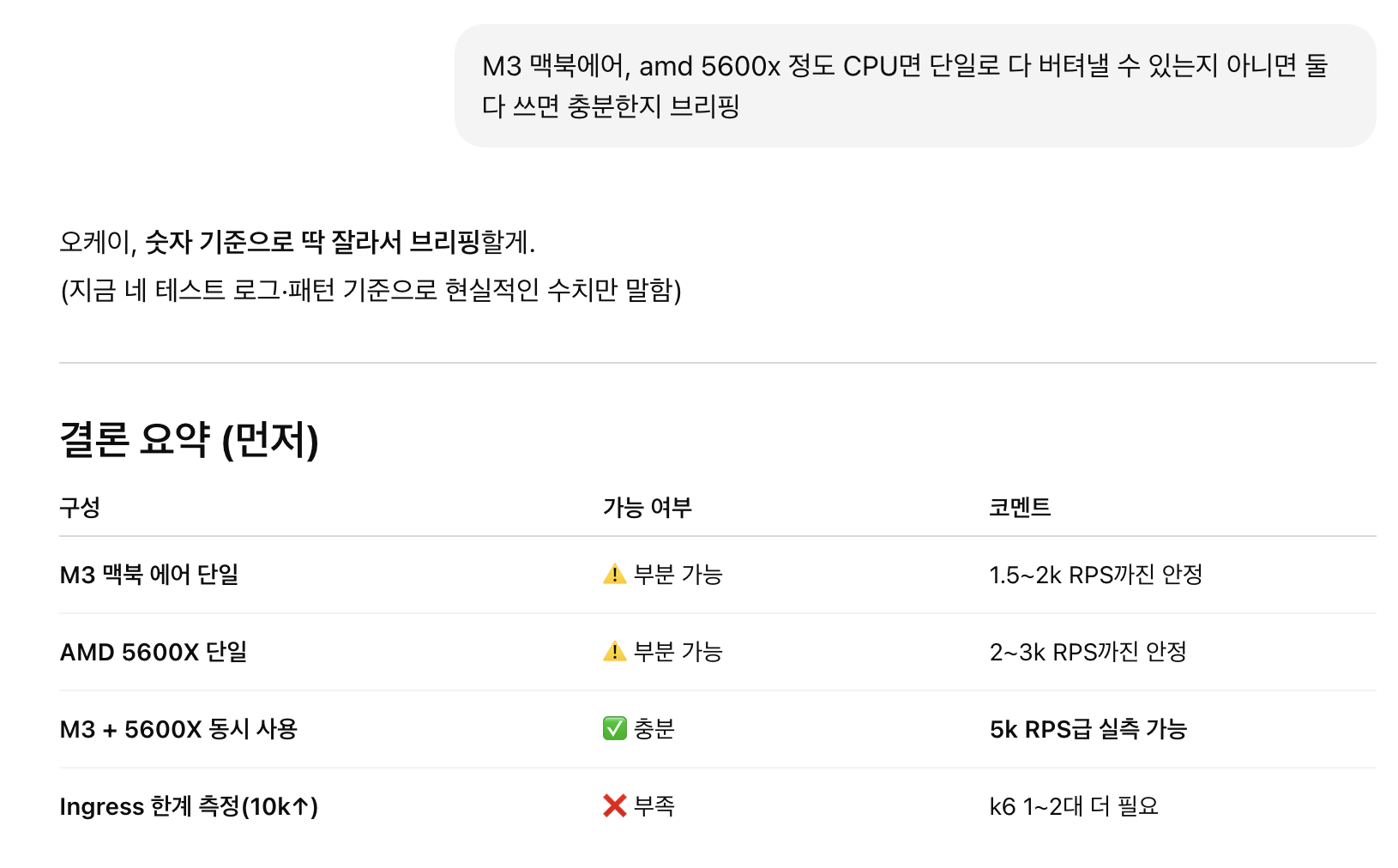
- 다만 이렇게 두대로 나눠서 구축하려면 OS도 다르고 하니까 k6 부하테스트 결과를 하나로 묶어서 볼 수 있도록 InfluxDB를 별도로 운영해야한다는 피드백을 받았다
- 흠.. 근데 이걸 해볼거였으면 맨 첫번째 실험부터 이렇게 해봤어야 비교 가능하고, 애초에 nginx 때와 달라 사용이나 접근 방법을 달리해야하는 쿠버네티스를 이런 식으로 계속 테스트를 이어가는게 큰 의미는 없겠다고 판단하였음
- 특히, nginx는 내가 진행한 모든 로직을 이해하고 진행한 반면, 쿠버네티스는 큰 줄기만 이해할뿐 디테일한 요소는 이해가 떨어져서 더 진행하는 것이 성장에 의미 없겠다는 판단하에 중지하였음
- 그래도 pod가 자동으로 늘어나는 것과 오케스트레이션이 되는 편의성까지는 체험해 볼 수 있었던 것이 좋았다
- 앞으로 실무에 가게 되면 실제론 어떻게 쓰는지, 어떤 식으로 쓸 때 더 좋은지 경험해볼 수 있으면 이런 개인 플젝, 실험에 더 도움이 될 것이라고 생각하는 기회였다
'Infra > DevOps' 카테고리의 다른 글
| 맥북에서 VPN 사용 시 주의할 점 (feat. WireGuard) (0) | 2025.12.12 |
|---|---|
| iptable-nft 환경에서 VPN 서버 구축하기 (feat. WireGuard) (0) | 2025.12.12 |
| Flannel이란? (feat. 쿠버네티스, Kubernetes, K8s) (2) | 2025.12.07 |
| 쿠버네티스(Kubernetes, K8s) 실험과 배운 것들에 대한 회고록 (0) | 2025.12.06 |
| 쿠버네티스(Kubernetes, K8s) 구축 과정에 마주한 에러들 (0) | 2025.12.03 |